O artigo selecionado para reprodução foi o "Conversão Texto-Fala para o Português Brasileiro Utilizando Tacotron 2 com Vocoder Griffin-Lim" de Rodrigo Kobashikawa Rosa, Danilo Silva. Nele os autores treinam o modelo Tacotron para gerar TTS para audio em português brasileiro. Algo que o modelo original Tacotron não era capaz de fazer.
Nele os autores se utilizam de um conjunto de dados chamado Common Voice para treinar o modelo Tacotron e gerar audio em português brasileiro.
Para mais informações de como rodar este projeto clique aqui para ir ao repositório com instruções.
Ao tentar executar os passos definidos no artigo tivemos bastante problemas de compatibilidade com o hardware para executar as funções, portanto nesta reprodução nos ateremos a utilizar uma outra implementação e outro modelo, mas avaliar de maneira manual este outro modelo da mesma maneira que foi avaliada no artigo (contagem de erros de pronúncia e palavras ignoradas pelo modelo). Utilizamos neste artigo modelos TTS que são multilinguais (modelos com capacidade de gerar para diversas linguas, inclusive português em alguns casos). Avaliaremos separadamente alguns modelos da mesma forma que o artigo original para avaliar a capacidade destes modelos de gerar sentenças em português brasileiro. Os modelos que decidimos utilizar foram: XTTS e YOUR-TTS. Ambos das implementações disponíveis neste repositório do COQUI-AI
No artigo os autores avaliam a qualidade do modelo a partir de contagens manuais de "palavras puladas" (palavras que foram ignoradas pelo tacotron no momento da sintetização de voz) e palavras pronunciadas de maneira incorreta. O artigo pode ser lido no DOI:10.14209/sbrt.2021.1570727280. A partir da técnica de avalaiação do autores, fizemos um trabalho manual de verificação dos audios que geramos com os dois modelos (XTTS e YOUR_TTS). A planilha de erros obtidos a partir da análise manual pode ser obtida neste link e com isso obtivemos a seguinte tabela de erros:
| Tipo de Erro | XTTS | YOUR TTS |
|---|---|---|
| Palavras puladas | 0 | 0 |
| Erros de pronúncia | 10 | 50 |
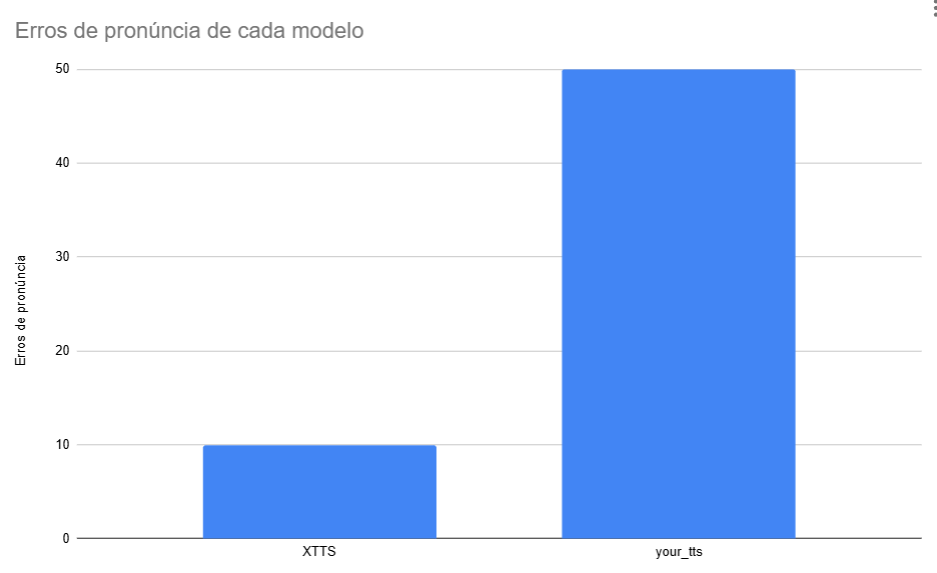
A partir desta tabela é possível notar que obtivemos um total de 0 erros de palavras puladas para ambos os modelos. Mas obtivemos um total de 10 erros de pronúncia para o modelo XTTs e 50 erros de pronúncia para o modelo YOUR-TTS. O resultado dos audios obtidos a partir dos modelos é possível ouvir na tabela abaixo. Os audios do modelo XTTs possuem uma qualidade melhor, mais natural e humana. Já os audios do modelo YOUR-TTS são mais robóticos e de qualidade um pouco menor tanto de pronúncia quanto de entonação.
| Sentença | XTTS | YOUR TTS |
|---|---|---|
| Esse tema foi falado no congresso. | ||
| Leila tem um lindo casaco. | ||
| O analfabetísmo é um problema chato. | ||
| O casarão foi vendido sem pressa. | ||
| Agindo com união ainda rende mais. |