Relatório de Fine-tuning do F5-TTS
Bem-vindo ao relatório do meu experimento de fine-tuning usando o F5-TTS com o corpus em português. Repositório: https://github.com/SWivid/F5-TTS
Configuração do Ambiente
- GPU: NVIDIA RTX 4060 Ti
- Driver: Game Ready 581.15 28 de agosto de 2025
- PyTorch: 2.4.0 + CUDA 12.4
- Dataset: TTS-Portuguese-Corpus
- Checkpoint Base:
firstpixel/F5-TTS-pt-br/model_last.safetensors
Metodologia
- Conversão dos áudios para 24kHz
- Geração do
raw.arrow,duration.jsonevocab.txt - Execução do
finetune_cli.pycom:- Epochs: 10 (teste inicial)
- Batch size: 1
- Mixed Precision: fp16
Resultados Parciais
Durante o treinamento foram gerados checkpoints salvos em ckpts/ptbr_char_test/.
Aqui estão alguns exemplos de saída:
Áudio Utilizado para gerar
Áudio gerado
Prints da aplicação
Aqui alguns prints do processo de treino:
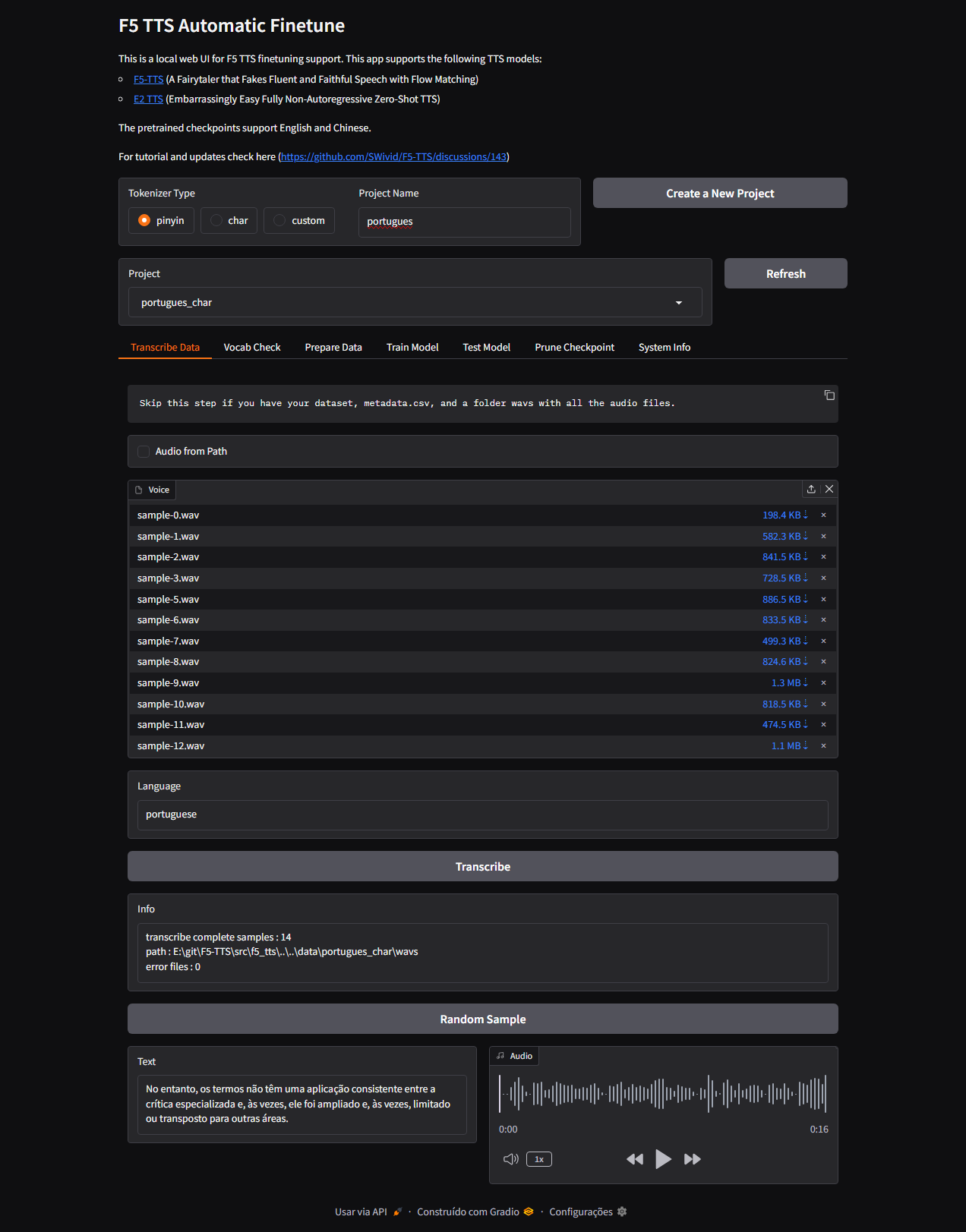
Figura 1: Interface do Gradio usada no treino.
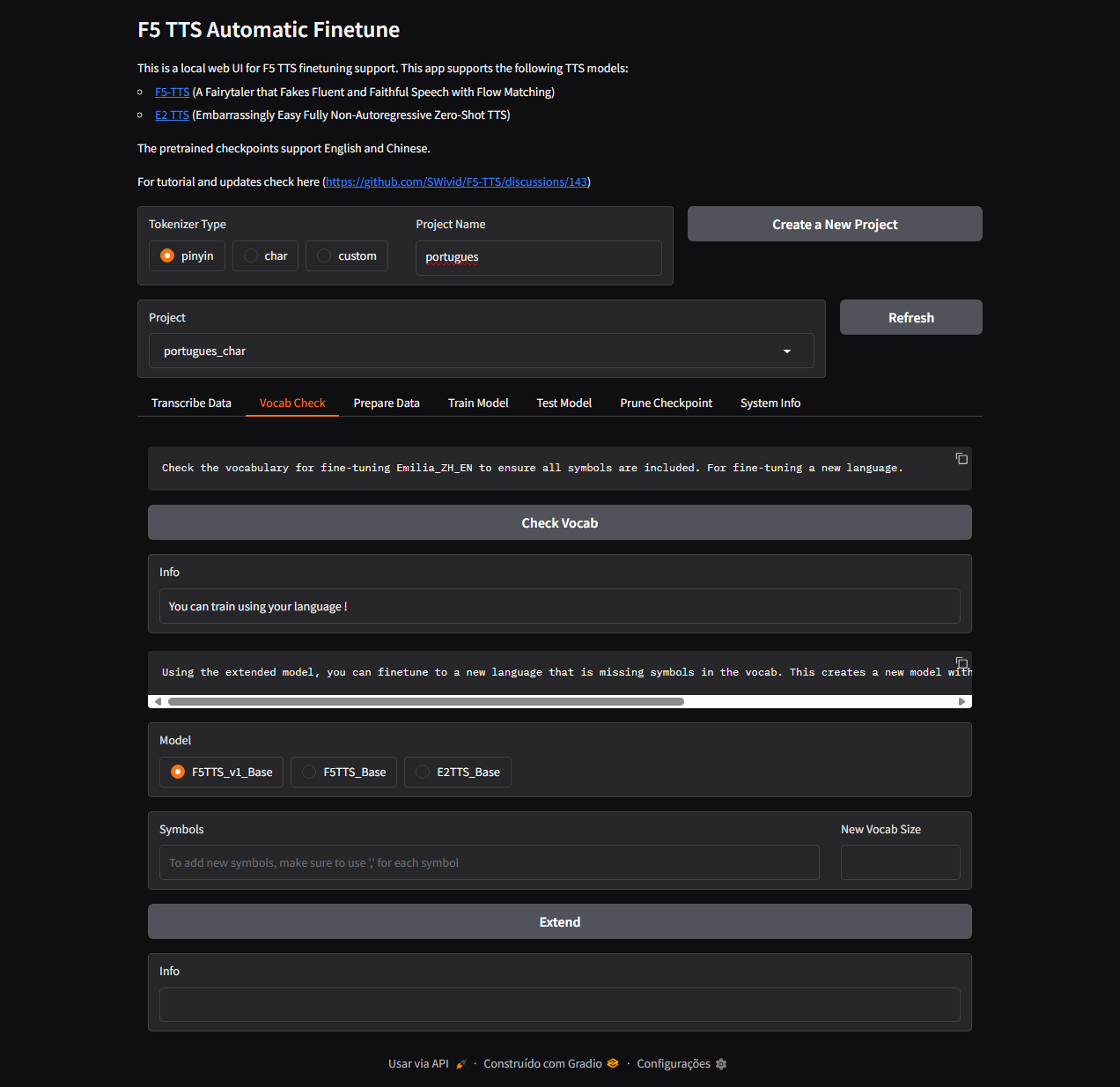
Figura 2: Interface do Gradio usada no treino.
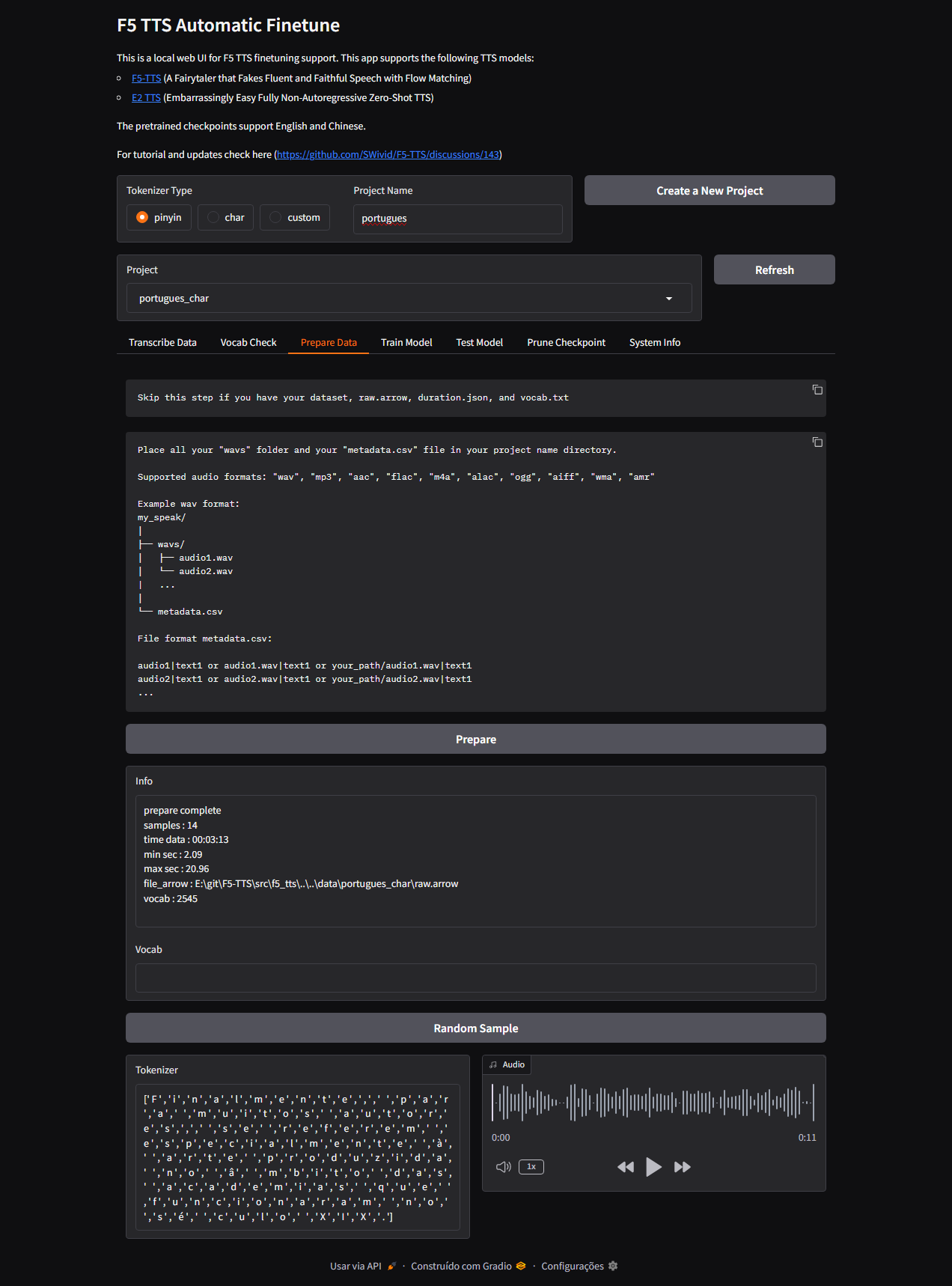
Figura 3: Interface do Gradio usada no treino.
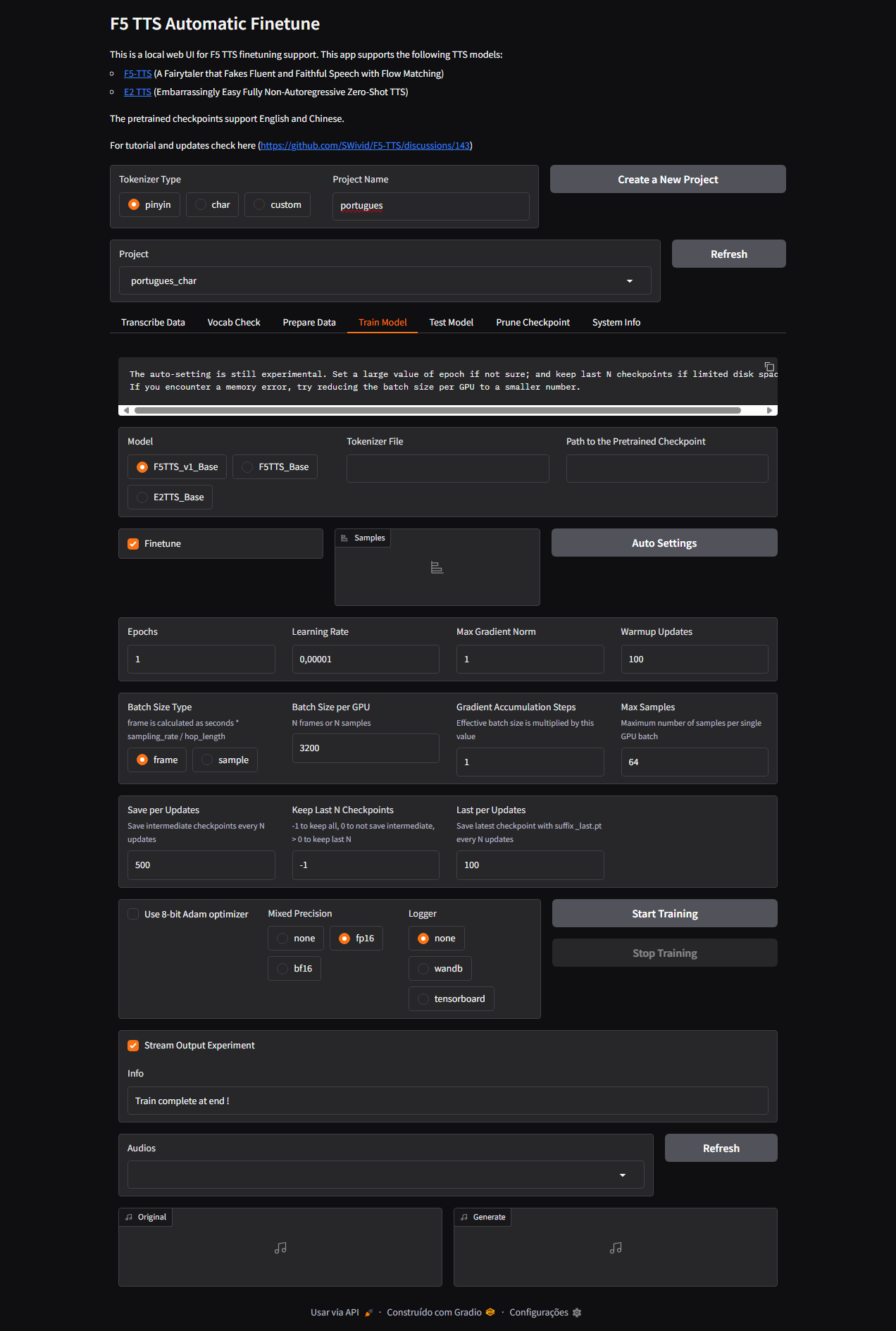
Figura 4: Interface do Gradio usada no treino.
Figura 5: Interface do Gradio usada no treino.
Figura 6: Interface do Gradio usada no treino.
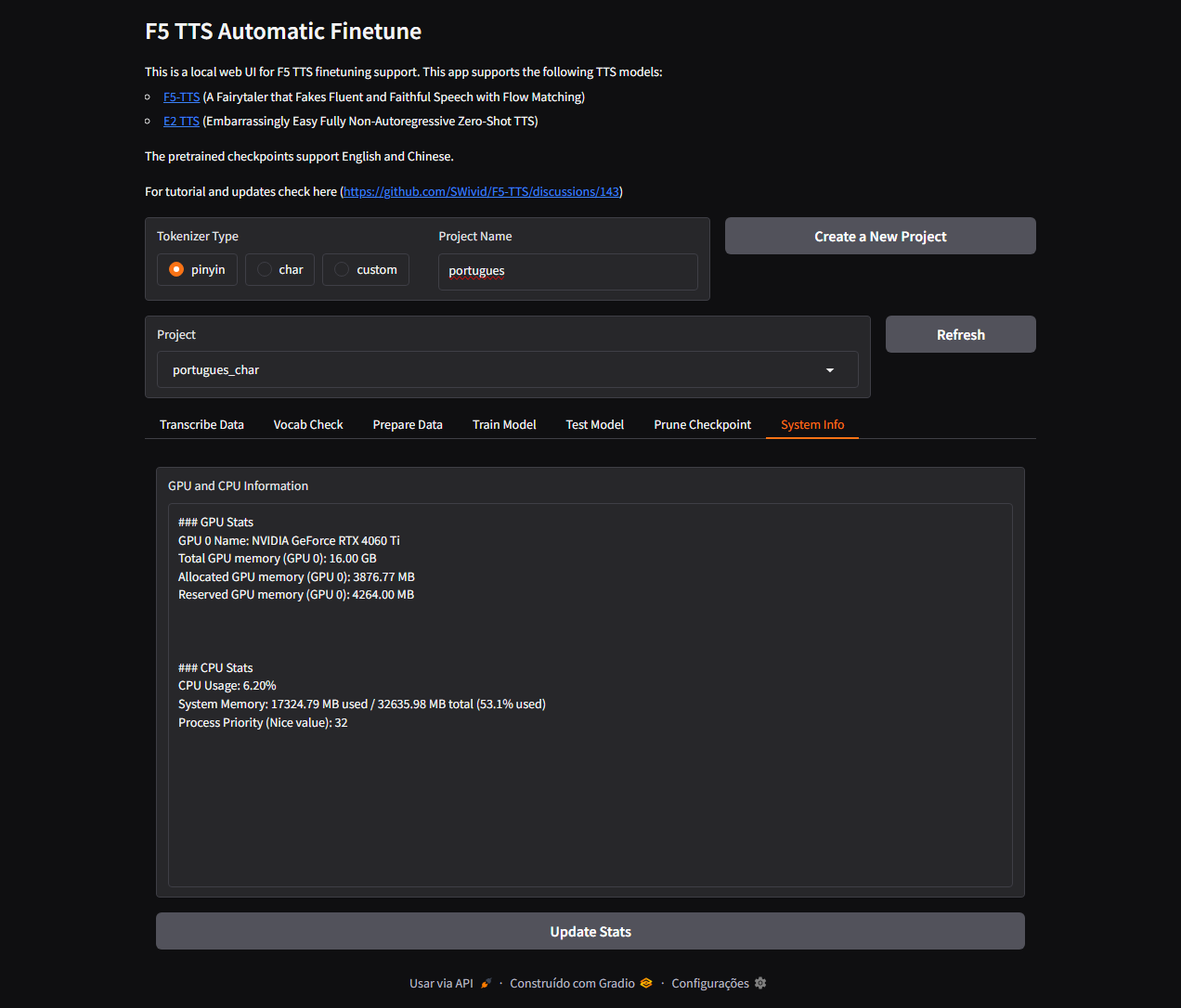
Figura 7: Interface do Gradio usada no treino.
Próximos Passos
- Aumentar número de épocas (>=50)
- Avaliar métricas de qualidade perceptiva (MOS)
- Testar vocoder alternativo (BigVGAN)
Código para rodar
conda create -n f5-tts python=3.10 -y
conda activate f5-tts
pip install --upgrade pip
pip install torch==2.4.0+cu124 torchaudio==2.4.0+cu124 --extra-index-url https://download.pytorch.org/whl/cu124
pip install -e .
pip install accelerate peft datasets gradio librosa soundfile
pip install pandas datasets soundfile librosa pyarrow
f5-tts_finetune-gradio
vocab: data/ptbr_char/vocab.txt
checkpoint: ckpts/ptbr_firstpixel/model_last.safetensors